简介
Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据。官方解释如下:
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
Beautiful Soup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度。
一个简单案例
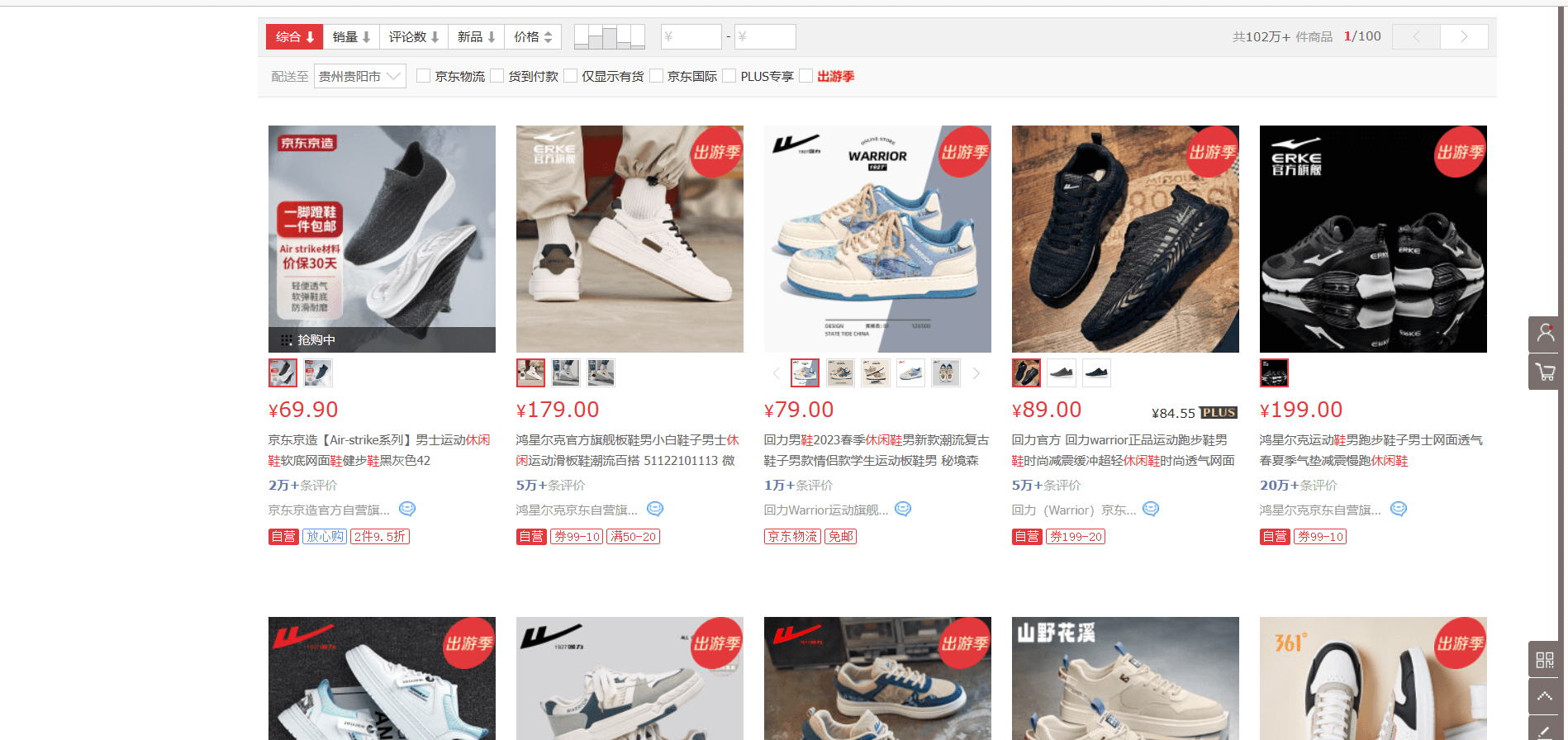
该案例使用Beautiful Soup简单爬取一个京东的网页数据
代码
import requests
from bs4 import BeautifulSoup
import pandas as pd
import openpyxl
#请求网站,获取到网页资源
date=requests.get("https://search.jd.com/Search?keyword=%E4%BC%91%E9%97%B2%E9%9E%8B&enc=utf-8&wq=%E4%BC%91%E9%97%B2%E9%9E%8B&pvid=04a7485c9360491bbb049acec91927e4")
#对网页资源进行解析
soup=BeautifulSoup(date.content,"html.parser")
#对网页资源进行补全和格式化
soup.prettify()
#获取到单个商品的div
list=soup.find_all("div",class_="gl-i-wrap")
#新建一个数组,保存鞋子的信息
arr=[]
for i in list:
#获取鞋子的名字
list_name=(i.find_all("div",attrs={"class","p-name"}))[0].find_all("em")[0].get_text()
#获取鞋子的价格
list_price=(i.find_all("div",attrs={"class","p-price"}))[0].find_all("i")[0].get_text()
#获取鞋子的图片链接
list_img=(i.find_all("div",attrs={"class","p-img"}))[0].find_all("img")[0].get("data-lazy-img")
#将获取到的信息添加到数组中
arr.append([list_name,list_price,list_img])
#新建一个pandas的数据,并往其中填入arr数组的内容
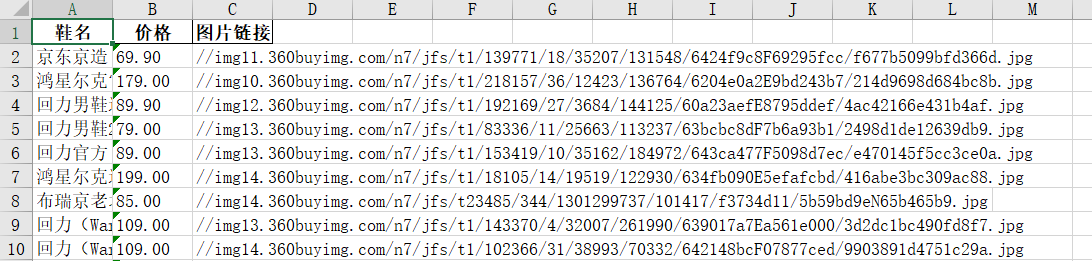
excel=pd.DataFrame(arr,columns=["鞋名","价格","图片链接"])
#将pandas数据转化为Excel表格,并在本地保存
excel.to_excel("demo1.xlsx",sheet_name='demo1',index=False)Excel文件
Beautiful Soup的一些语法
-
获取标签的属性:
soup.find("img").get("data-lazy-img") -
获取标签的内容:
soup.find("img").get_text() -
获取所有的 div 标签:
soup.find_all("div") -
获取所有的 div 标签(限定其属性):
soup.find("div", attrs = {"class":"p-price"}) -
查找一个元素:
soup.find() -
查找一组元素:
soup.find_all("div") -
将素组存为文件:
pandas.DataFrame(_array).to_csv("./phone_info.csv")
tips: find和find_all方法的区别,find方法返回第一个匹配到的对象,而find_all返回所有匹配到的对象,是一个列表
joblib库中的Parallel实现并行下载
一个简单例子
Parallel(n_jobs=-1)(delayed(download_pdf)(pdf_link) for pdf_link in pdf_links)具体来说,Parallel(n_jobs=-1)创建了一个Parallel对象,其中n_jobs=-1表示将使用所有可用的CPU核心并行下载PDF文件。delayed(download_pdf)是一个装饰器函数,它将download_pdf函数延迟执行,并返回一个可调用的对象。最后,(delayed(download_pdf)(pdf_link) for pdf_link in pdf_links)是一个生成器表达式,它为每个PDF链接创建了一个函数调用。
简单点说,delayed函数将你的函数转化为延迟执行的函数,因为要多线程运行,for pdf_link in pdf_links的意思是将pdf_links列表中的每一个元素都作为延迟执行的函数的传入参数
 wechat
wechat alipay
alipay